
티스토리 뷰

가장 주요한 특징은 선입선출의 자료구조를 가집니다.
구현체로는 보통 Circular Buffers, Linked List를 사용한다고 합니다.
Java에서는 Collection Framework에 포함되어 있으며
Queue Interface를 Array Deque, Linked List, Priority Queue로 구현을 하기도 합니다.
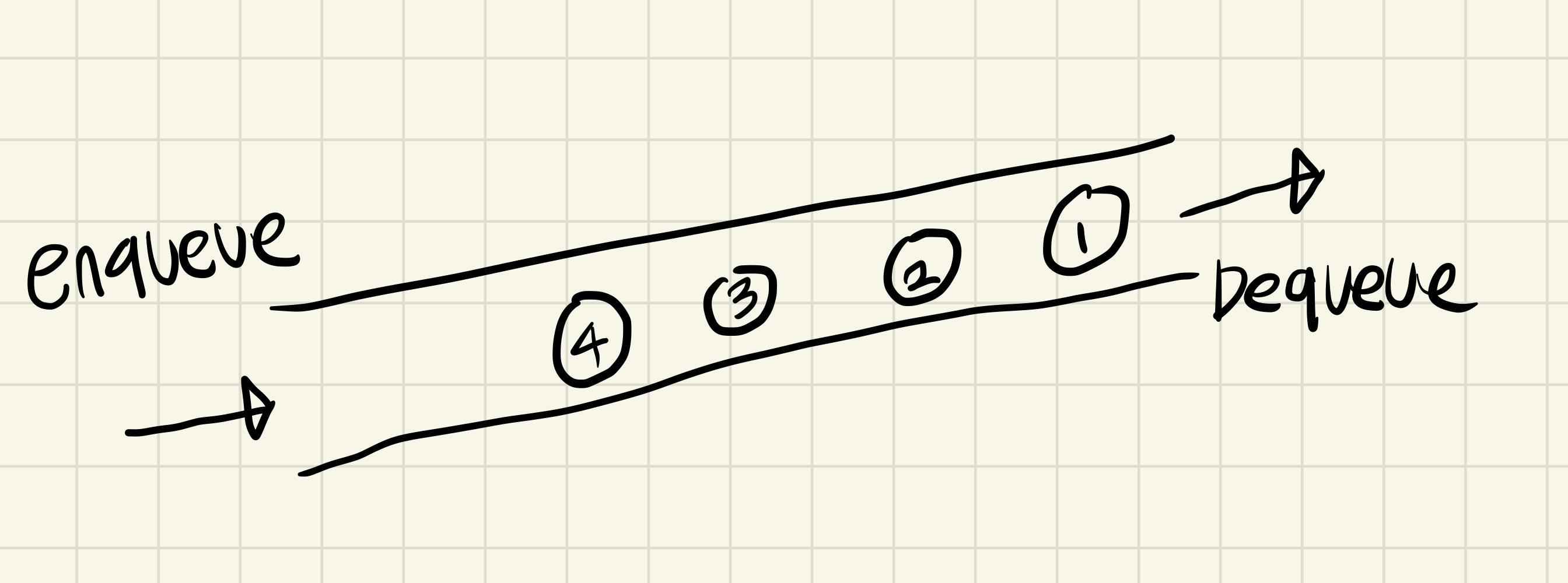
버퍼의 기능으로도 활용되며
너비우선탐색 알고리즘(BFS)에도 활용이 가능합니다.

Queue를 구현하는 방법
선형 배열을 사용하여 구현하기

Deque를 하여 index 0의 요소가 사라지게 되었습니다. 배열로 Queue를 구현하면
사용되는 과정에서 원소들이 뒤로 밀리는 현상이 발생할 수 있습니다.
이런 현상을 해결하기 위해 Deque연산마다 요소를 앞으로 당기면 비효율적입니다.
그렇다고 계속 뒤로 밀리게 하면 공간낭비가 심합니다.
이럴 때 Queue의 구현체로 원형의 형태로 사용하는 배열을 사용하거나
연결리스트를 사용할 수 있습니다.
🍩
원형 배열을 사용하여 구현하기
선형 개념을 사용하는 배열을 사용하면 위의 설명처럼 문제가 생깁니다.
배열을 원형의 형태로 생각하여 큐의 기능을 생각해 봅니다.
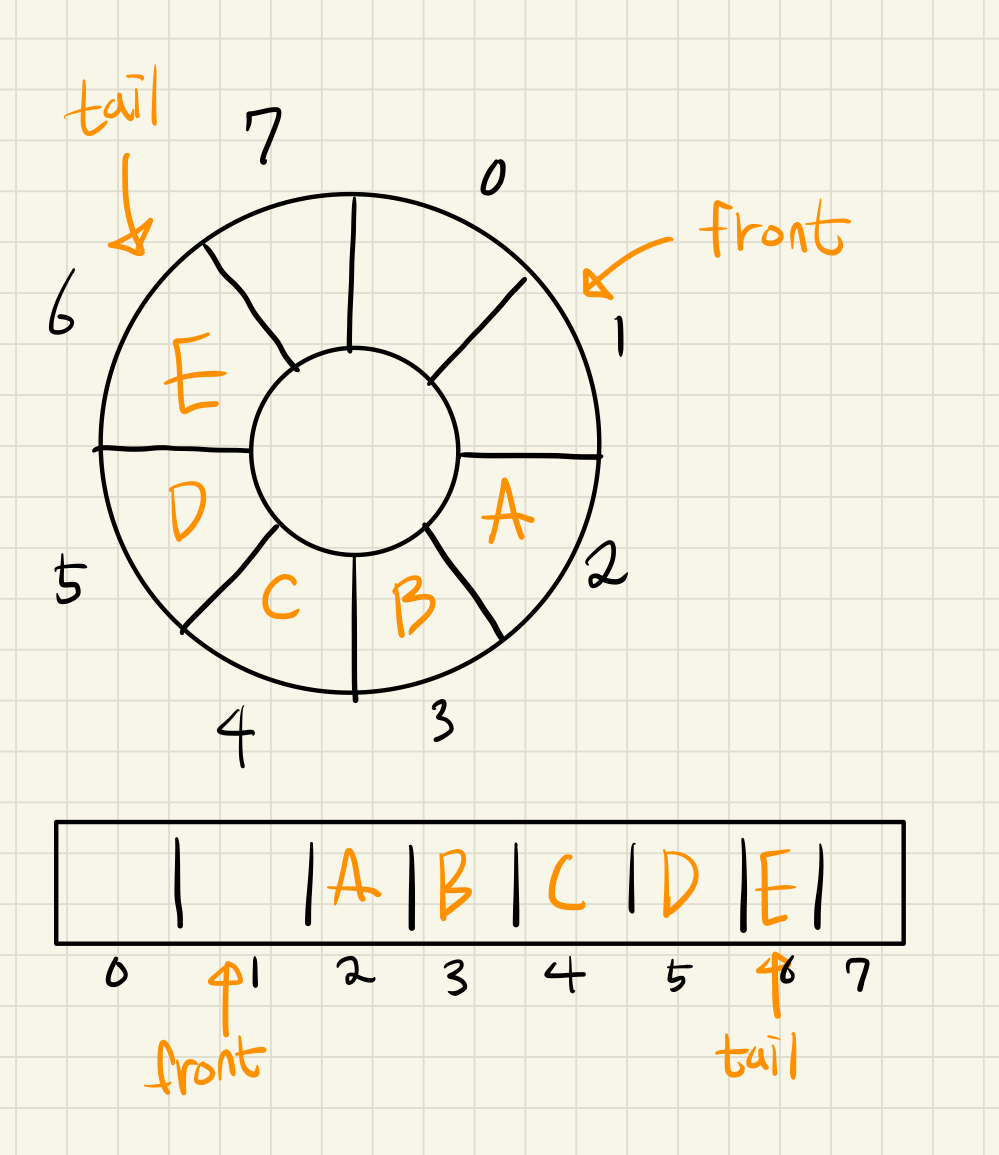
tail과 front의 개념이 추가되었습니다.
tail은 마지막으로 삽입된 요소의 위치이며 front는 제일 먼저 삽입된 요소의 이전 위치입니다.
이제 위에 도넛같이 생긴 도형을 돌면서 요소를 삽입, 삭제하게 됩니다.
선형 배열로 구현한 큐에서의 문제점인 Deque작업 시 요소들의 위치를 변경해 준다거나
사용되지 않는 공간이 남는 거나 하는 문제가 사라집니다.

물리적으로는 메모리에 인접한위치에 일렬로 나열된 배열이지만
front와 tail의 값이 시계방향으로 돌면서 마치 원형의 배열에 넣는 것 같이 사용됩니다.
배열을 원형으로 이미지화하여 큐를 구현하는 것을
Circular Queue, 원형 큐라고 표현합니다.

Java로 구현하는 큐
원형큐로 구현합니다.

기본 배열의 크기는 32로 설정합니다.
* size : 배열 안의 요소의 개수
* capacity : 배열자체의 크기

생성자입니다. capacity(배열크기)를 받거나 기본생성자로 인스턴스 생성 시 32를 배열의 크기로 사용합니다.

적절한 배열의 크기를 위해 재조정하는 기능입니다.
요소의 개수가 배열의 크기 10분의 1도 안 되는 상황에서 배열의 크기를 크게 잡을 이유는 없습니다.
혹은 더 많은 요소를 넣어야 하면 배열의 크기를 늘려줄 필요가 있습니다.
외부에서 접근하면 잘못된 사용으로 망가질 수 있으니 private으로 잡아둡니다.
newCapacity의 크기를 가지는 큐의 배열을 새로운 배열로 교체합니다.
newArray는 새로운 배열이며 반복문을 돌면서 기존배열의 값을 새로운 배열의
0번째 위치부터 새로 쌓아갑니다.
(기존배열은 CG의 대상으로 유도하기 위해 null로 참조를 바꿔줍니다.)
새로운 배열에서는 0부터 시작하기 때문에 front와 tail의 값을 재조정합니다.
핵심로직은 반복문입니다.
// i = newArray index, j = oldArray index
for(int i = 1, j = front + 1; i <= size; i++, j++) {
// front의 값이 capacity를 넘어가면 보정
newArray[i] = array[j % originCapacity];
}i : 새로운 배열에 할당되는 위치
j : 기존 배열의 요소 위치
"j"에는 처음 "front + 1"을 할당합니다. 원형큐에서는 front의 위치가 요소 이전 위치를 바라봅니다.
새로운 배열의 "i"의 위치에 " j % originCapacity"위치의 요소를 넘겨줍니다.
나머지 연산을 하는 이유는 front의 값이 기존 배열크기를 넘어갈 수 있습니다.
예로 들어 front가 3이며 capacity가 5일 때 "array[front + 1 % capacity]"는
4 % 5는 4가 나옵니다. 이렇게 된다면 배열의 마지막요소를 바라보고
front가 4라면 (4 + 1) % 5 = 0 첫 번째 요소를 바라보게 되며
front가 capacity를 넘어갈 때 보정해 주는 기능을 해줍니다.

큐에서는 기본적으로는 한 방향으로 넣고 뺄 수 있습니다.
tail은 큐의 마지막 요소를 바라보고 있습니다.
고려해야 하는 것은 배열에 더 이상 넣을 공간이 없는 것입니다.
이러한 경우는 length와 비교하여 이전에 만든 resize() 기능을 사용하여 2배로 늘려줍니다.
기존 크기보다 조금만 늘려준다면 조금씩 늘어날 때마다 계속 resize연산이 들어갑니다.
과감하게 늘려줍니다.

처음에 요소의 개수가 0이면 null을 반환합니다. (add(), remove()와 다르게 큐의 연산은 예외를 뱉지 않습니다.)
제거할 위치(front)를 선정하여 배열에서 제거해 줍니다.

제거하기 이전에 반환하기 위해 제거될 요소의 참조를 얻습니다.
E type으로 캐스팅을 해서 얻습니다.
@SuppressWarnings("unchecked")
배열은 Object[]로 잡혀있지만 저희는 enque, deque연산에서 E type으로
분명히 받기 때문에 검증되지 않은 연산에 대하여 경고를 받지 않아도 됩니다.

요소를 제거할 때 현재 배열의 크기가 기본 배열크기(32)보다 크며
현재 요소의 개수가 현재 배열크기/4보다 작으면 resize를 진행합니다.
= 알맹이는 없는데 껍데기가 크다
껍데기의 크기를 재조정해줍니다.
기본 배열크기와 현재 배열크기/2중 큰 값으로 현재 배열크기를 변경합니다.
= 못해도 기본 배열크기만큼은 잡아준다.

요소의 크기가 0이면 null을 넘기며 front값 보정 후 요소를 꺼내 반환합니다.

"idx"는 배열에 접근하기 위해 사용되며
"i"는 몇 번 수행하였는지 확인하기 위해 사용됩니다.
특이한 점은 반복할 때마다 "i"는 +1을 해주지만 "idx"는 보정연산을 계속해주며 들어갑니다.
"idx"도 +1 연산을 해주면 front가 capacity의 값을 초과할 수도 있습니다.
i가 size값까지만 진행하게 됩니다.
size는 배열 내 요소의 크기이니 그 이상 해줄 필요가 없습니다.
이렇게 반복문이 종료될 때까지 동일성검사를 통과하지 못하면 false를 반환합니다.
'자료구조 알고리즘' 카테고리의 다른 글
| BinarySearchTree 학습 (0) | 2023.02.05 |
|---|---|
| Heap 학습 (0) | 2023.02.02 |
| LinkedListDeque 학습 (0) | 2023.01.31 |
| Deque 학습 (0) | 2023.01.29 |
| hash map 학습 (0) | 2023.01.07 |
- Total
- Today
- Yesterday
- 코딩테스트
- 자바
- 알고리즘
- ㅃ
- 스택
- 스타트업
- 백준 제로
- jre
- 백준
- 관계설정
- springboot
- JPA
- 개발자채용
- boot 일대다
- JDK
- jre8
- JDK8
- 백엔드
- jdk11
- jvm
- mappedby
- 문제
- 프로그래머
- 백준 제로 자바
- 다대일
- Spring
- jre11
- 자사서비스
- boot
- java8
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |