
티스토리 뷰
🏷 map?
key와 value로 이루어지며 key는 중복이 되어서는 안됩니다.
프로필
이름 : 김민수
키 : 178
key : "이름", value : "김민수"
key : "키", value : 178
위와 같이 2개의 데이터가 한쌍을 이룰때 사용하면 효과적입니다.
만약 프로필 1개에 이름같이 논리적으로 1개만 있어야하는 key의
중복이 허용되면 데이터의 신뢰성이 떨어집니다.
언어차원에서도 map 자료구조의 구현체들이 중복 key값은 막아두었습니다.
Java에서는 HashMap, TreeMap, LinkedTreeMap같은 구현체가 있습니다.
🔢 hash?
데이터를 다루는 기법중 하나로
임의의 데이터를 받아 hashFunction에 넣으면 고정된 길이의 값으로 만드는 것을 의미합니다.
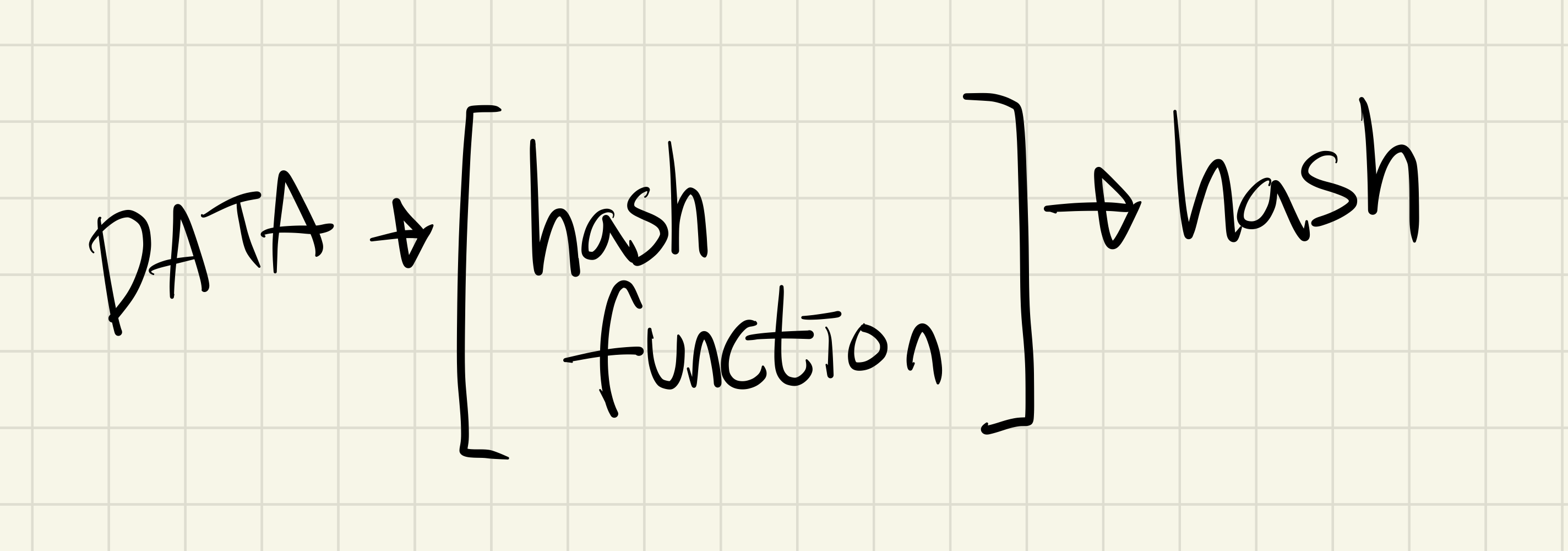
임의의 알고리즘을 가진 hash function에 데이터를 넣으면 1개의 값에 대하여 동일한 값을 반환하지만
다른 값들이 동일한 hash를 가질 수 있습니다.
아래와 같은 상황을 해시 충돌이라고 표현합니다.
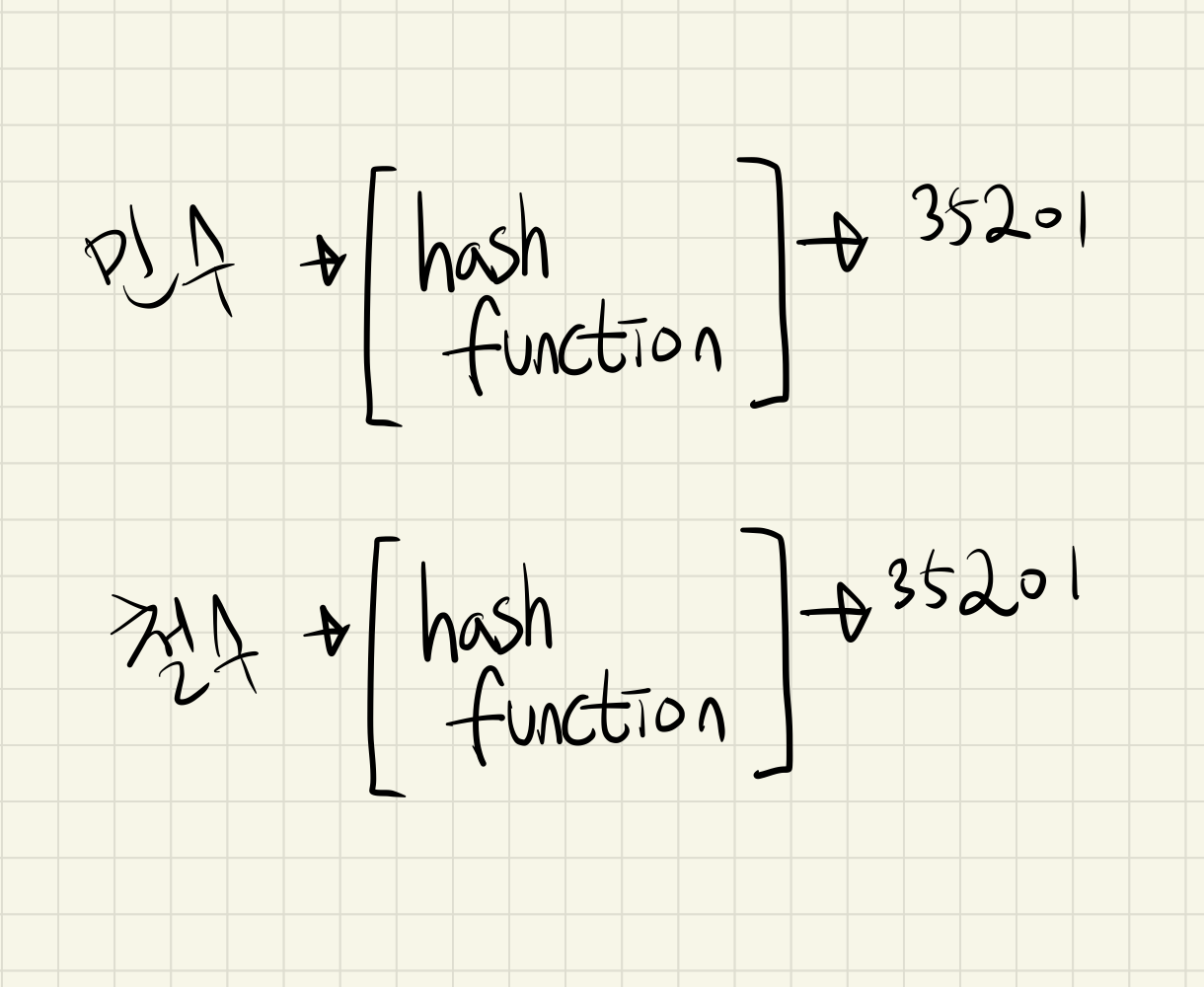
위와 같은 상황때문에 민수라는 값은 35201을 정확하게 추론하지만 35201은 민수를 정확하게 추론할 수 없습니다.
이와 같은 특징을 사용하면 사용자의 크리티컬한 정보의 평문을 제공하지 않고 서드파티앱의 서비스를 이용할 수 있습니다.
이런한 것을 단방향 암호화라고도 합니다.
✨hashMap?
hash와 Map의 특징이 결합된 자료구조입니다.
검색, 삽입, 삭제등에서 hash값을 table의 key로 사용하여 자료구조를 핸들링합니다.
이번 포스팅에서의 설명은 배열에 기반한 table의 경우입니다.
배열과 비이슷하다.
공통점은 둘다 임의의 index로 데이터에 random access 하여 검색시 시간복잡도가 보통 상수이며
다른점은 배열은 요소의 논리적 순서와 물리적 순서가 동일하지만 해시맵은 논리적 순서와 물리적 순서가 다릅니다.
hash code(hashing 결과)자체가 table의 index로 사용되기 때문에
사용자의 데이터가 hash function을 거치며 table에 예측할 수 없는 순서로 배치 될 것입니다.

데이터를 hashing하여 table에 적재하는 과정에서 생기는 문제점..
hash function의 알고리즘에 따라서 hash code의 범위가 최대 어디까지 나올까를 알아야합니다.
Java의 String class의 hashCode()는 int type을 반환합니다.

2의 32승까지가 경우의 수입니다. hash code를 그대로 index로 사용하니 저 메서드가 반환하는 값을 커버링하려면
hashTable의 크기가 2의 32승이 되어야하며 추가적으로 음수도 고려해야합니다. 큰범위때문에 hash table의 크기를 작게하면
아래와 같은 문제가 생깁니다.

hash table의 크기를 30으로 설정하였는데 hashCode의 값이 -5나 100이 나온다면
table[hashcode] = data;
위의 코드는 가차없이 예외를 반환합니다.
이러한 경우를 위해서 어떤 해시함수를 사용하던 받은 결과에 대하여
배열을 기반으로 사용하려면 값을 양수로 변경 그리고 table의 크기로 나누어 나머지 값을 Index로 사용하여
넣을 index의 범위를 0 <= hash < m으로 좁혀줘야 합니다.
음수 index를 가지는 배열은 없으며 배열의 크기를 넘는 위치에 할당할 수는 없기때문입니다.
Math.abs(hash) % m
이제 hash 범위를 좁혀줬다면 아래와 같이 충돌이 발생가능성이 존재합니다.
N가지 경우의수를 N - (1 .. N-1 )가지의 경우의 수로 표현하려 한다면 중복이 발생하게 됩니다.

데이터 삽입시 table의 버켓(= hash)에 이미 데이터가 존재하는 경우를 표현
이러한 해시충돌(hash collision)을 해결하는 방법으로는 체이닝(chaining), 개방 주소법(open address)이 존재합니다.
체이닝 : 충돌이 발생하면 해당 버켓의 value에 linked list같은 방식으로 node를 연결해서
1개의 주소값에 2개이상의 데이터를 표현합니다.
개방 주소법 : 충돌이 발생하면 다른 빈 버켓에 데이터를 추가한다. 빈 버켓을 찾는방식은 선형, 제곱, 이중해시 같은 것들이 존재

hash table에서 검색실패시(cache miss) 체이닝방식과 개방 주소법의 성능차이
table의 용적률 0.75부터 캐시미스횟수가 기하급수적으로 올라갑니다.
java에서 제공하는 HashMap의 경우
고도화되었지만 전체적인 흐름을 알기위해 간략하게 구현하였습니다.
instance val와 constructor
public class HashMap {
private int capacity = 10;
private int size = 0;
private double resizingRatio = 0.75;
private Item[] table;
public HashMap() {
table = new Item[capacity];
}
...capacity : table의 최초의 크기
size : table에 들어간 요소의 개수
resizingRatio : table의 크기를 늘리는 임계점 (정확한 알고리즘과 시간복잡도없이는 구현안해도 됨)
table : 실제로 데이터가 들어가는 배열
hash function
private int getHash(String key) {
int hash = 0;
for(int i = 0; i < key.length(); i++) {
hash = ((hash << 5) - hash) + key.charAt(i);
}
return hash;
}문자열에 포함된 문자를 ASCII로 변환하고 31을 곱한것의 합산을 반환하였습니다.
31이란 숫자는 소수이면 홀수이기 때문입니다. (이게 좋다고 합니다..^^;)
비트연산이 더빠르기 때문에 31을 곱하는것과 동일한 결과를 내는 (i << 5) - i 식을 사용하였습니다.
3 * 31 <- 93
(3 << 5) - 3 <- 93
put function
public void put(String key, String value) {
// 원래 map은 null도 허용합니다.
if(key == null) throw new IllegalArgumentException("key is null");
int hash = getHash(key);
// hash값을 capacity 범위로 축약
int pos = Math.abs(hash) % capacity;
// 해시충돌 없음
if(table[pos] == null) {
table[pos] = new Item(key, hash, value);
size++;
// 해시충돌 있음
}else {
//개방 주소법, 버켓에 순차적으로 접근하면서 공간을 찾음
for (int i = pos; i < capacity; i++) {
if (table[i] == null) {
table[i] = new Item(key, hash, value);
size++;
break;
// 순차적으로 접근하면서 값이 있을때 hash와 equals()가 모두 true이면 중복된 요소로 판단 + 삭제 여부
} else if (table[i].hash == hash && table[i].key.equals(key) && !table[i].isDeleted) {
break;
}
}
}
// 용적률 임계치보다 size가 이상이거나, table의 마지막 버킷이 사용중이라면 resizing
if(size >= capacity * resizingRatio | table[size-1] != null) {
table = getResizingTable(this.table);
capacity = table.length;
}
}
remove function
public boolean remove(String key) {
// put에서 null을 무시하였으니 동일하게 구현
if(key == null) throw new IllegalArgumentException("key is null");
int hash = getHash(key);
int pos = Math.abs(hash % capacity);
for(int i = pos; pos < capacity; i++) {
// 개방 주소법중 순차적으로 넣는 방식을 선택하였으므로
// 삭제요소가 테이블에 존재하는 경우 pos값부터 +1씩 탐색하며 null이 발견되기전에 요소를 발견함
if(table[i] == null) return false;
// 삭제할때 null로 밀어버리면 pos부터 capacity까지 모두 탐색해야함
if(table[i].hash == hash && table[i].key.equals(key) && !table[i].isDeleted) {
table[i].isDeleted = true;
size--;
break;
}
}
return true;
}
resize
private Item[] getResizingTable(Item[] table){
// 현재 capacity의 2배크기의 배열을 새로 생성
Item[] resizingTable = new Item[capacity * 2];
// null과 삭제된 요소는 모두 버린다.
// 삭제된 요소를 그대로 들고가면 동등한 오브젝트가 죽어있는 상태, 살아있는 상태 2개가 공존할 수 있다.
// 해시충돌확률도 상승함.
for(Item item : table) {
if(item == null || item.isDeleted) continue;
// 버켓에 등록해둔 hash값을 새로운 capcity 범위로 재분배한다.
resizingTable[item.hash % (capacity * 2)] = item;
}
return resizingTable;
}
get function
public Object get(String key) {
if(key == null) throw new IllegalArgumentException("key is null");
int hash = getHash(key);
int pos = Math.abs(hash % capacity);
for(int i = pos; pos < capacity; i++) {
if(table[i] == null) break;
// 1. 동일한 hash
// 2. 동등한 object
// 3. 삭제된요소가 아님
// 3가지가 true면 요소 반환
if(table[i].hash == hash && table[i].key.equals(key) && !table[i].isDeleted) return table[i].value;
}
return null;
}
테이블 요소타입
private class Item {
public String key; // key 평문
public int hash; // hash
public String value; // value
public boolean isDeleted; // 삭제 여부
private Item(){}
public Item(String key, int hash, String value){
this.key = key;
this.hash = hash;
this.value = value;
this.isDeleted = false;
}
}
'자료구조 알고리즘' 카테고리의 다른 글
| BinarySearchTree 학습 (0) | 2023.02.05 |
|---|---|
| Heap 학습 (0) | 2023.02.02 |
| LinkedListDeque 학습 (0) | 2023.01.31 |
| Deque 학습 (0) | 2023.01.29 |
| Queue 학습 (0) | 2023.01.24 |
- Total
- Today
- Yesterday
- boot 일대다
- JPA
- 개발자채용
- jdk11
- 백준 제로 자바
- JDK8
- 백준
- 자바
- 다대일
- 프로그래머
- jre
- 스타트업
- springboot
- jre11
- 관계설정
- 코딩테스트
- jre8
- ㅃ
- 문제
- mappedby
- Spring
- JDK
- 알고리즘
- boot
- 백엔드
- java8
- jvm
- 스택
- 자사서비스
- 백준 제로
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |